
Сценарии использования GPU

Аренда GPU для машинного обучения позволяет в разы ускорить ML и обучение моделей генеративного ИИ.
Реализация моделей на базе сервера с графическим процессором обеспечивает высокую скорость ответа сервисов ИИ.
Облачные GPU снижают порог входа и позволяют запускать ИИ-проекты без крупных инвестиций и долгой подготовки инфраструктуры.
Использование GPU повышает производительность анализа изображений, 3D-моделирования, рендеринга и обработки видео.
Облачные GPU как платформа высокопроизводительных вычислений ускоряют time to market новых цифровых продуктов и сервисов.
Отраслевые сценарии
- антифрод
- кредитный скоринг
- риск-модели
- collection
- голос/чат-боты
- ассистенты операторов
- RAG по внутренним базам
- OCR/распознавание документов
- урегулирование убытков в страховании
- персонализация
- next best offer
- отток

- персонализация/рекомендации
- прогноз спроса
- динамическое ценообразование
- «умные» кассы
- компьютерное зрение в магазинах/складах (полка, OOS, потери, безопасность)
- генИИ для контента/карточек товаров/ассистентов операторов и сотрудников

- сейсмика/интерпретация
- моделирование пластов
- оптимизация добычи (HPC/ML)
- цифровые двойники установок/процессов
- оптимизация режимов
- предиктивная аналитика оборудования
- компьютерное зрение: контроль безопасности, СИЗ, периметр, дефекты, факел/утечки, качество продукции

- компьютерное зрение на конвейерах и обогатительных фабриках: контроль качества, грансостава и засоров
- контроль безопасности: люди/техника, опасные зоны, СИЗ
- оптимизация энергопотребления и производственных режимов
- предиктивная аналитика оборудования
- элементы автономности и диспетчеризации: карьеры, транспорт

Аренда GPU в облаке — модели видеокарт и характеристики GPU-серверов
Карта |
Примеры использования |
Архитектура |
GPU Memory |
GPU Bandwidth |
| NVIDIA H100 Tensor Core GPU | Обучение ИИ и ресурсоёмкие ИИ-приложения | Hopper | 80 ГБ | 2 ТБ/с |
| NVIDIA A100 Tensor Core GPU | Обучение ИИ, научные вычисления, аналитика данных | Ampere | 80 ГБ | 1 935 ГБ/с |
| NVIDIA L40S GPU | Инференс, 3D-графика и рендеринг, ML с повышением производительности | Ada Lovelace | 48 ГБ | 864 ГБ/с |
| NVIDIA L4 Tensor Core GPU | Инференс, обучение и тонкая настройка небольших моделей, 3D-графика и рендеринг | Ada Lovelace | 24 ГБ | 300 ГБ/с |
| NVIDIA T4 Tensor Core GPU | Инференс, ML, глубокое обучение и виртуальные рабочие столы | Turing | 16 ГБ | 300 ГБ/с |
Основные преимущества аренды GPU в облаке K2 Cloud
Подберем тип инстанса с необходимым соотношением vCPU/RAM/дисков, предоставим высокопроизводительные ВМ для нетиповых задач.

Вы можете получить GPU на базе выделенного сервера, сконфигурированного под ваши задачи, с RAM до 4ТБ и процессорами AMD EPYC/Intel Xeon Gold (4 ГГц и выше).

Технология NVLink позволяет подключить до четырех видеокарт в одну ВМ или выделенный сервер.

Аренда сервера GPU из К2 Облака снижает CAPEX и ускоряет запуск проекта. Вы получаете мощности и качественное сопровождение без расходов на собственные ресурсы. Оптимизация затрат — до 75% по сравнению с использованием GPU on premise.

Строим изолированный контур для работы с LLM-моделями на чувствительных данных в безопасном облаке: защита ПДн по 152-ФЗ до УЗ-1, безопасность платёжных систем PCI DSS 4.0 и финансовых операций ГОСТ Р 57580.1-2017, R=0,95.

Вы сможете самостоятельно запускать, настраивать и отключать инстансы с GPU с помощью Terraform и API.

![]()
Сервис Managed Kubernetes с GPU позволяет быстро разворачивать кластеры с графическими картами и актуален для компаний, развивающих ИТ-инфраструктуру на базе контейнеров.
-
сокращение объёма работ по настройке инфраструктуры
-
оптимизация ресурсов: разделение одной GPU на изолированные инстансы с помощью технологии MIG
-
гибкое масштабирование: добавление узлов с GPU на пиках нагрузки
![]()
Запустите ИИ-проект любой сложности за 20 минут в облачной инфраструктуре с мощными GPU-серверами. Платформа K2 NeuroTech в К2 Облаке — это полный цикл машинного обучения в одном интерфейсе, от подготовки данных до мониторинга моделей.
-
импортонезависимость за счёт open source и ПО из российского реестра
-
SSO и ролевая модель доступа
-
приватный инференс-сервис для безопасной работы с корпоративными данными
-
профессиональная поддержка наших инженеров
Инструменты платформы
- среды разработки
![]()
![]()
- пайплайны CI/CD
![]()
- векторные базы данных
![]()
![]()
- управление файловыми системами
![]()
- создание агентов и мультиагентных систем
![]()
Конфигурации и цены на аренду GPU‑серверов в облаке
Pay as you go, почасовая тарификация
Скидка до 25% при коммите на аренду видеокарты на 3/6/12 месяцев
Архитектура облачного сервиса GPU
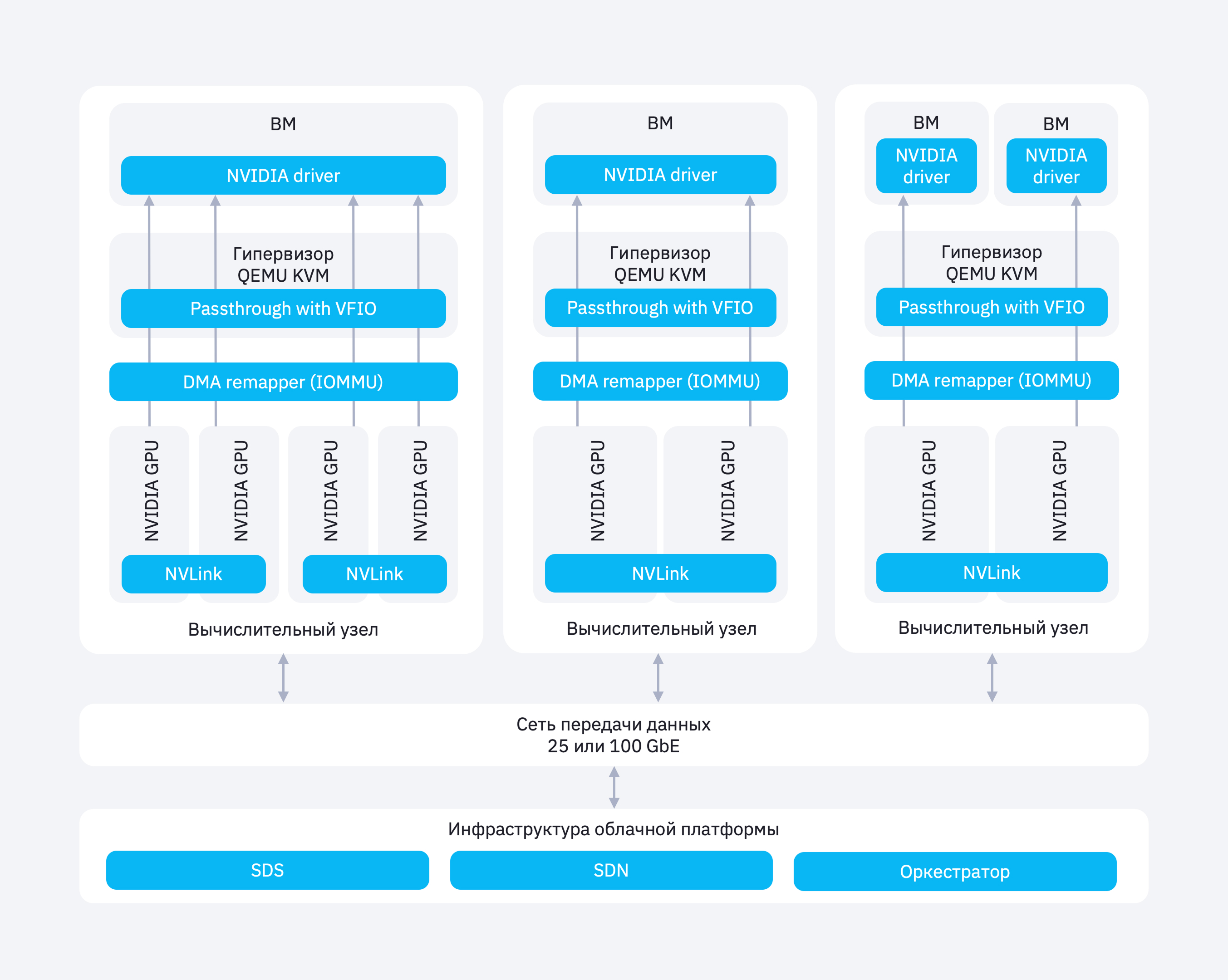
Как арендовать GPU‑сервер в облаке
Ваш персональный менеджер K2 Cloud проанализирует вашу задачу и предложит вариант решения — аренда GPU в облаке или выделенный сервер GPU.
Вы можете провести бесплатный тест-драйв одной или нескольких конфигураций облачного GPU.
Подготовка инфраструктуры с GPU в облаке занимает от 10 мин, выделенного сервера GPU — от 3 рабочих дней

Часто задаваемые вопросы
В конфигурации сервиса GPU можно использовать любой тип дисков из доступных в К2 Облаке — HDD, SSD, высокопроизводительные SSD+ и NVMe с пропускной способностью до 300 000 IOPS.
Сервис реализован на базе сети ЦОД уровня Tier III, расположенных в Москве и Санкт-Петербурге.
Минимальное время аренды сервера с видеокартой — 1 час. Если вы уже используете К2 Облако, то сможете в любой момент создать ВМ с GPU внутри своей VPC (для подключения свяжитесь с вашим менеджером K2 Cloud).
SLA 99,95% на доступность виртуальных машин.
Вы можете развернуть ВМ с GPU на базе любой из следующих операционных систем: AlmaLinux, Rocky Linux, Oracle Linux, openSUSE Leap, Fedora, CentOS, OPNsense, FreeBSD, Windows Server DC.
























Новости













Почему K2 Cloud
К2 Облако
Комплексные проекты для крупного бизнеса
Безопасность на всех уровнях
Professional Services Team
Сопутствующие продукты

ИИ-консалтинг

Базы данных

Managed Kubernetes

Аренда облачного сервера
