Keras и Tensorflow – классификация текста

Классификация текста с помощью TensorFlow и Keras.
Описание задачи
Некоторое время назад коллеги попросили меня помочь им в решении задачи автоматической классификации текста на множество категорий. В качестве исходного датасета для машинного обучения мне предоставили базу данных, в которой было около 90 тыс обращений в HelpDesk, разбитых на 222 категории. Названия категорий конфиденциальны и потому скрыты. Важно здесь то, что заявки распределяются по категориям весьма неравномерно.
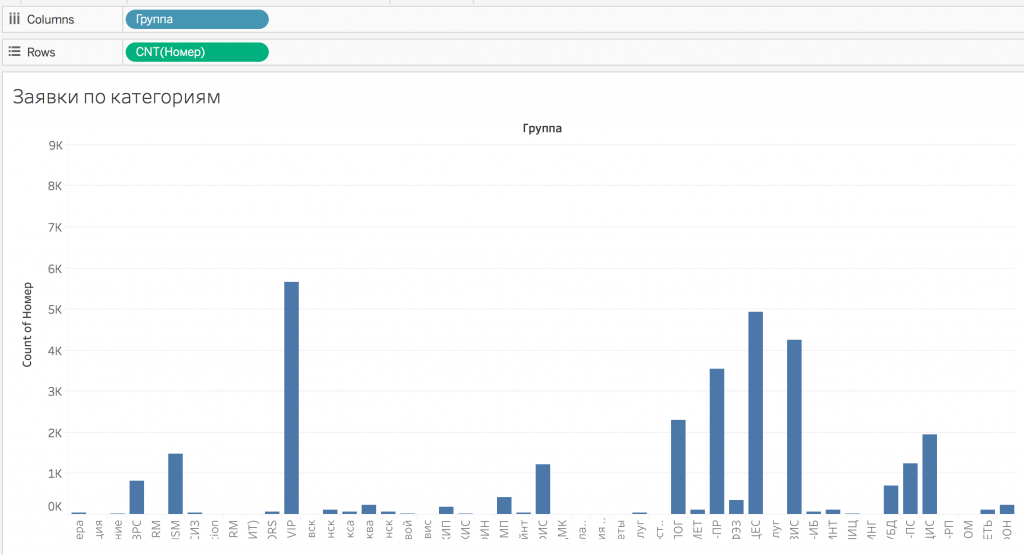
В этой статье я покажу, как я учился это делать и как получил результат правильного определения категории в 98,7% случаев.
Контролируемое обучение
После того, как задача определена, можно делиться ее решением. Вообще говоря, данная задача представляет собой задачу контролируемого обучения (supervised learning), и все задачи похожего типа в настоящее время решаются по следующему алгоритму:
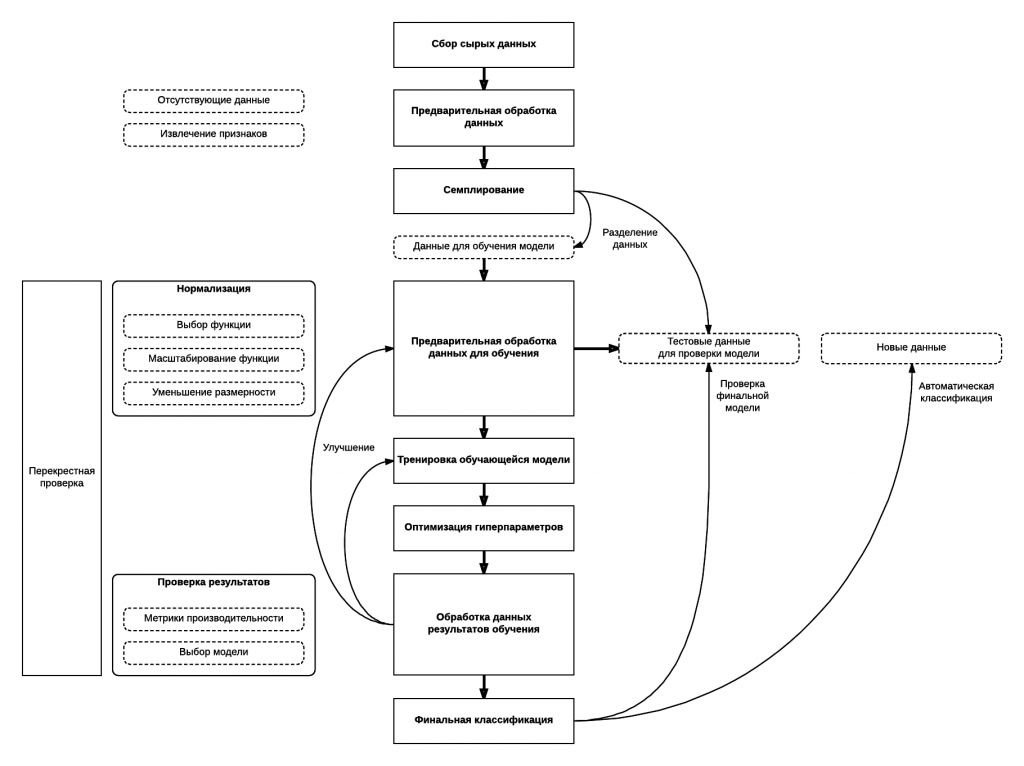
Немного забегая вперед, скажу, что суть задачи классификации текста после его предварительной подготовки и очистки сводится к тому, чтобы составить словарь всех слов в ваших текстах, заменить каждое слово на число — уникальный номер слова в вашем словаре, выровнять длину каждого текста до нужного вам размера (обычно это количество слов в максимально длинном тексте), а дальше к представленным в таком виде данным можно применять абсолютно любой алгоритм классификации. Какой покажет лучшую производительность, тот и используйте.
Сбор сырых данных
В моем случае сырые данные были представлены в СУБД MS SQL в следующем виде
|
Номер обращения |
Категория |
Описание заявки |
Офис |
Дата создания |
Другие поля |
|
12345 |
Категория 1 |
Текст заявки 1 |
Офис 1 |
Дата 1 |
...... |
|
67890 |
Категория 2 |
Текст заявки 2 |
Офис 2 |
Дата 2 |
...... |
|
...... |
...... |
...... |
...... |
...... |
...... |
Эти данные были успешно выгружены в Pandas DataFrame следующим образом:
import pymssql
import pandas as pd
db = {
'host': '192.168.123.228',
'username': 'db_user',
'password': 'db_password',
'database': 'db_name',
'table': 'dbo.table_name'
}
conn = pymssql.connect(server=db['host'], user=db['username'],password=db['password'])
stmt = "SELECT * FROM {database}.{table}".format(database=db['database'], table=db['table'])
df = pd.read_sql(stmt, conn)
Предварительная обработка данных
На этом этапе мы должны проанализировать данные: посмотреть на их распределение, понять, есть ли в данных, которые мы будем анализировать отсутствующая информация, в каком виде эти данные представлены. Следом необходимо эти данные привести к единому виду. В нашем случае был построен график распределения заявок по категориям и оценен вид текстовых данных при помощи:
df.head()
Сразу стало понятно, что в DataFrame приехали данные, содержащие «\r\n», английский и русские слова, различные спецсимволы, которые необходимо было удалить. Попутно все слова были приведены к их нормальной форме при помощи pymorphy2
import pymorphy2
import re
ma = pymorphy2.MorphAnalyzer()
def clean_text(text):
text = text.replace("\\", " ").replace(u"╚", " ").replace(u"╩", " ")
text = text.lower()
text = re.sub('\-\s\r\n\s{1,}|\-\s\r\n|\r\n', '', text) #deleting newlines and line-breaks
text = re.sub('[.,:;_%©?*,!@#$%^&()\d]|[+=]|[[]|[]]|[/]|"|\s{2,}|-', ' ', text) #deleting symbols
text = " ".join(ma.parse(unicode(word))[0].normal_form for word in text.split())
text = ' '.join(word for word in text.split() if len(word)>3)
text = text.encode("utf-8")
return text
df['Description'] = df.apply(lambda x: clean_text(x[u'Описание заявки']), axis=1)
В этом блоке кода определена функция clean_text(text):, которая принимает строку, разбивает весь текст (все предложения) на отдельные слова, выбрасывает все слова (преимущественно предлоги), длинна которых меньше 3-х символов. В самом конце функция clean_text(text): применяется построчно к столбцу с именем «Описание заявки» в нашем DataFrame, и результат выполнения (очищенный текст) записывается в отдельный новый столбец с именем «Description» (ну не люблю я русские имена в заголовках таблиц).
Вы наверняка обратили внимание на то, что столбец «Категория» содержит текстовые данные. Их необходимо заменить на числовые данные, поставив в соответствие названию каждой категории ее уникальный номер. Делается это следующим образом:
# создадим массив, содержащий уникальные категории из нашего DataFrame
categories = {}
for key,value in enumerate(df[u'Категория'].unique()):
categories[value] = key + 1
# Запишем в новую колонку числовое обозначение категории
df['category_code'] = df[u'Категория'].map(categories)
total_categories = len(df[u'Категория'].unique()) + 1
print('Всего категорий: {}'.format(total_categories))
Т.к. записей у меня достаточно много, и их обработка занимает существенное время, то для ускорения работы в дальнейшем я рекомендую вам переодически сохранять изменения вашего DataFrame, например, в формате pickle:
df.to_pickle('dataframe_ver_1.pkl')
Прочитать данные в DataFrame быстро и удобно можно в любой момент времени:
df = pd.read_pickle('dataframe_ver_1.pkl')
Итак, перед началом обучения нам осталось привести все описания заявок к единому виду и разбить данные. Крайне рекомендую перемешать строки всего DataFrame-а, чтобы в обучающий и проверочный наборы данных попали все типы категорий:
df = df.sample(frac=1).reset_index(drop=True)Семплирование
Итак, после очистки текста и разделения его на слова, необходимо разделить все строки с обращениями на два набора данных: данные для тренировки модели и данные для проверки ее работы. Для этого определим массивы с описанием заявок и вычислим максимальную длинну описания:
descriptions = df['Description']
categories = df[u'category_code']
# Посчитаем максимальную длинну текста описания в словах
max_words = 0
for desc in descriptions:
words = len(desc.split())
if words > max_words:
max_words = words
print('Максимальная длина описания: {} слов'.format(max_words))
maxSequenceLength = 55
Настало время начать использовать Keras — высокоуровневый фреймворк, работающий поверх TensorFlow, позволяющий нам решать большое количество рутинных задач т.к., например, преобразование текста в числовые последовательности для анализа и быстрое моделирование нейронных сетей для машинного обучения.
Для вышеописанной задачи преобразования текста в числовые последовательности в Keras есть специальный класс Tokenizer, который мы и будем использовать:
from keras.preprocessing.text import Tokenizer
# создаем единый словарь (слово -> число) для преобразования
tokenizer = Tokenizer()
tokenizer.fit_on_texts(descriptions.tolist())
# Преобразуем все описания в числовые последовательности, заменяя слова на числа по словарю.
textSequences = tokenizer.texts_to_sequences(descriptions.tolist())
Обучающий и тестовый наборы данных будут содержать массив чисел, обозначающих описание заявки (X) и категорию, к которой обращение относится (y). Соответственно, данные для тренировки будут записаны в переменные X_train, y_train, а данные для проверки алгоритма обучения будут записаны в переменные X_test, y_test. Для этого я написал небольшую функцию:
def load_data_from_arrays(strings, labels, train_test_split=0.9):
data_size = len(strings)
test_size = int(data_size - round(data_size * train_test_split))
print("Test size: {}".format(test_size))
print("\nTraining set:")
x_train = strings[test_size:]
print("\t - x_train: {}".format(len(x_train)))
y_train = labels[test_size:]
print("\t - y_train: {}".format(len(y_train)))
print("\nTesting set:")
x_test = strings[:test_size]
print("\t - x_test: {}".format(len(x_test)))
y_test = labels[:test_size]
print("\t - y_test: {}".format(len(y_test)))
return x_train, y_train, x_test, y_testДанная функция принимает на вход массив с описаниями заявок strings, массив с числовым обозначением категории labels и переменную train_test_split нужную для варьирования количества данных для теста и верификации соответственно. По-умолчанию я использую 90% данных для тренировки, 10% для проверки результата.
Получим наборы данных:
X_train, y_train, X_test, y_test = load_data_from_arrays(textSequences, categories, train_test_split=0.8)Теперь было бы не плохо узнать с каким количеством слов в словаре мы имеем дело:
total_words = len(tokenizer.word_index)
print('В словаре {} слов'.format(total_words))
В моем случае в словаре оказалось 59400 слов.
Возвращаемся к условию задачи
Итак, в моей базе 98576 описаний заявок, 222 категории, в словаре 59400 слов, и максимальная длина описания 55 слов. Для решения задачи по категоризации я не буду использовать все 59 тыс слов, а возьму только 1000, что составляет примерно 1,7% всего словаря. Так мы существенно уменьшим количество расчетов и существенно ускорим процесс обучения.
Исходя из этих соображений, переопределим наши обучающие и тестовые данные:
# количество наиболее часто используемых слов
num_words = 1000
print(u'Преобразуем описания заявок в векторы чисел...')
tokenizer = Tokenizer(num_words=num_words)
X_train = tokenizer.sequences_to_matrix(X_train, mode='binary')
X_test = tokenizer.sequences_to_matrix(X_test, mode='binary')
print('Размерность X_train:', X_train.shape)
print('Размерность X_test:', X_test.shape)
print(u'Преобразуем категории в матрицу двоичных чисел '
u'(для использования categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)Все, предварительная подготовка данных закончилась, теперь можно заниматься тренировкой нейронной сети.
Классификация текста при помощи MLP (multilayer perceptron) модели
В примерах использования Keras вы найдете решение задачи классификации при помощи MLPи при помощи LSTM моделей. Последнюю необходимо будет немного оптимизировать именно под нашу задачу. Я покажу как это сделать далее.
Итак, определяем модель для обучения (MLP):
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Activation
from keras.layers import Dropout
# количество эпох\итераций для обучения
epochs = 10
print(u'Собираем модель...')
model = Sequential()
model.add(Dense(512, input_shape=(num_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(total_categories))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print(model.summary())
Обучаем полученную модель, записывая историю обучения в переменную history:
history = model.fit(X_train, y_train,
batch_size=32,
epochs=epochs,
verbose=1,
Как только модель обучится, нам останется только валидировать ее «успешность»:
score = model.evaluate(X_test, y_test,
batch_size=32, verbose=1)
print()
print(u'Оценка теста: {}'.format(score[0]))
print(u'Оценка точности модели: {}'.format(score[1]))
На моих данных эта модель показала 71% точности при классификации тестовых данных.
При желании можно построить график эффективности обучения:
import matplotlib.pyplot as plt
# График точности модели
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# График оценки loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()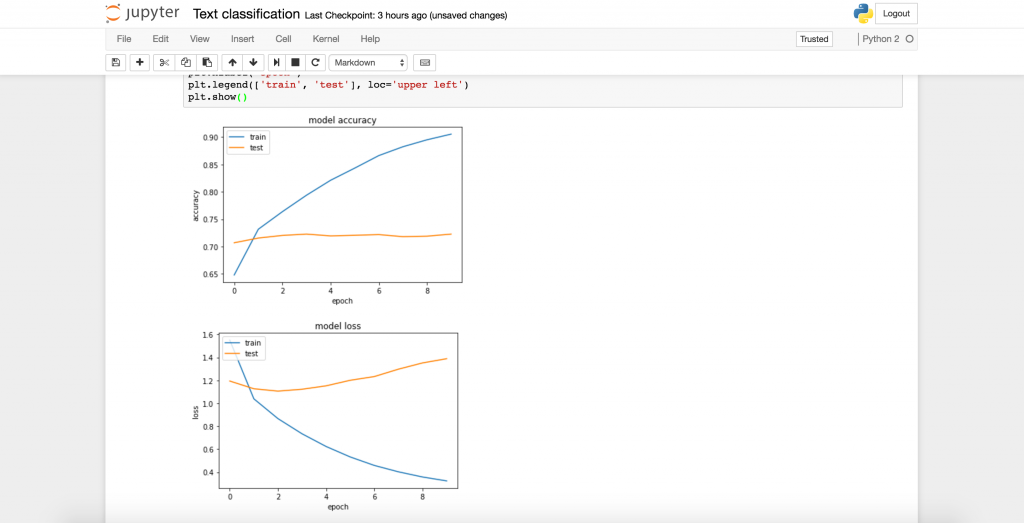
В моем случае эта модель показала не сногсшибательные результаты (даже при увеличении количества слов для анализа до 2000 я получил прирост производительности на 2% и примерно двукратное увеличение времени расчетов), поэтому я решил попробовать добиться успеха при помощи LSTM.
Классификация текста при помощи LSTM (long short-term memory) модели
Давайте попробуем использовать те же самые данные для этой модели и посмотрим на результат. Загружаем обучающую и тестовую выборку:
from keras.preprocessing.text import Tokenizer
# создаем единый словарь (слово -> число) для преобразования
tokenizer = Tokenizer()
tokenizer.fit_on_texts(descriptions.tolist())
# Преобразуем все описания в числовые последовательности, заменяя слова на числа по словарю.
textSequences = tokenizer.texts_to_sequences(descriptions.tolist())Используем то же самое распределение (это никак не скажется на результате, но данные снова не перемешиваем):
X_train, y_train, X_test, y_test = load_data_from_arrays(textSequences, categories, train_test_split=0.8)
# Максимальное количество слов в самом длинном описании заявки
max_words = 0
for desc in descriptions.tolist():
words = len(desc.split())
if words > max_words:
max_words = words
print('Максимальное количество слов в самом длинном описании заявки: {} слов'.format(max_words))
total_unique_words = len(tokenizer.word_counts)
print('Всего уникальных слов в словаре: {}'.format(total_unique_words))
maxSequenceLength = max_wordsДля уменьшения количества расчетов в модели уменьшим общий словарь, оставив в нем только 10% наиболее популярных слов:
vocab_size = round(total_unique_words/10)
Далее преобразуем данные для тренировки и тестирования в нужный нам формат:
print(u'Преобразуем описания заявок в векторы чисел...')
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(descriptions)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)
X_train = sequence.pad_sequences(X_train, maxlen=maxSequenceLength)
X_test = sequence.pad_sequences(X_test, maxlen=maxSequenceLength)
print('Размерность X_train:', X_train.shape)
print('Размерность X_test:', X_test.shape)
print(u'Преобразуем категории в матрицу двоичных чисел '
u'(для использования categorical_crossentropy)')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)Считаем количество категорий:
import numpy as np
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
encoder.fit(y_train)
y_train = encoder.transform(y_train)
y_test = encoder.transform(y_test)
num_classes = np.max(y_train) + 1
print('Количество категорий для классификации: {}'.format(num_classes))Определяем LSTM модель для обучения:
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM
# максимальное количество слов для анализа
max_features = vocab_size
print(u'Собираем модель...')
model = Sequential()
model.add(Embedding(max_features, maxSequenceLength))
model.add(LSTM(32, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(num_classes, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print (model.summary())Обучаем:
batch_size = 32
epochs = 3
print(u'Тренируем модель...')
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test))По окончанию процесса обучения оценим его результаты:
score = model.evaluate(X_test, y_test,
batch_size=batch_size, verbose=1)
print()
print(u'Оценка теста: {}'.format(score[0]))
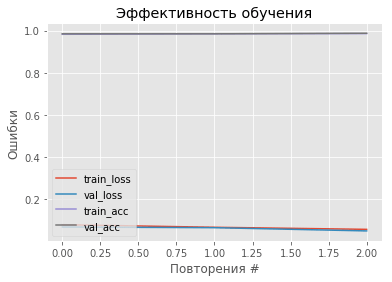
print(u'Оценка точности модели: {}'.format(score[1]))На моих данных эта модель показала 98,7% точности при классификации.
При желании снова можно построить график эффективности процесса обучения:
# Посмотрим на эффективность обучения
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use("ggplot")
plt.figure()
N = epochs
plt.plot(np.arange(0, N), history.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), history.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), history.history["acc"], label="train_acc")
plt.plot(np.arange(0, N), history.history["val_acc"], label="val_acc")
plt.title("Эффективность обучения")
plt.xlabel("Повторения #")
plt.ylabel("Ошибки")
plt.legend(loc="lower left")Или посмотреть на мой:
Небольшой бонус
Долгое время в статье существовала ошибка, которую получилось (дошли руки) исправить только сейчас. Вы наверняка видели ее в комментариях. В качестве извинения привожу пример наглядной проверки результатов классификации:
text_labels = encoder.classes_
for i in range(20):
prediction = model.predict(np.array([X_test[i]]))
predicted_label = text_labels[np.argmax(prediction)]
print(X_test.iloc[i][:50], "...")
print('Правильная категория: {}'.format(y_test.iloc[i]))
print("Определенная моделью категория: {}".format(predicted_label))Также посмотреть хорошо определяемые категории (темнее) и не очень хорошо определяемые категории (светлее) можно при помощи следующего кода:
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues, normalize=True):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title, fontsize=30)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, fontsize=22)
plt.yticks(tick_marks, classes, fontsize=22)
fmt = '.2f'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('Правильная категория', fontsize=25)
plt.xlabel('Определенная моделью категория', fontsize=25)
y_softmax = model.predict(X_test)
y_test_1d = []
y_pred_1d = []
for i in range(len(y_test)):
probs = y_test[i]
index_arr = np.nonzero(probs)
one_hot_index = index_arr[0].item(0)
y_test_1d.append(one_hot_index)
for i in range(0, len(y_softmax)):
probs = y_softmax[i]
predicted_index = np.argmax(probs)
y_pred_1d.append(predicted_index)
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from itertools import *
text_labels = encoder.classes_
cnf_matrix = confusion_matrix(y_test_1d, y_pred_1d)
plt.figure(figsize=(48,40))
plot_confusion_matrix(cnf_matrix, classes=text_labels, title="Confusion matrix")
plt.show()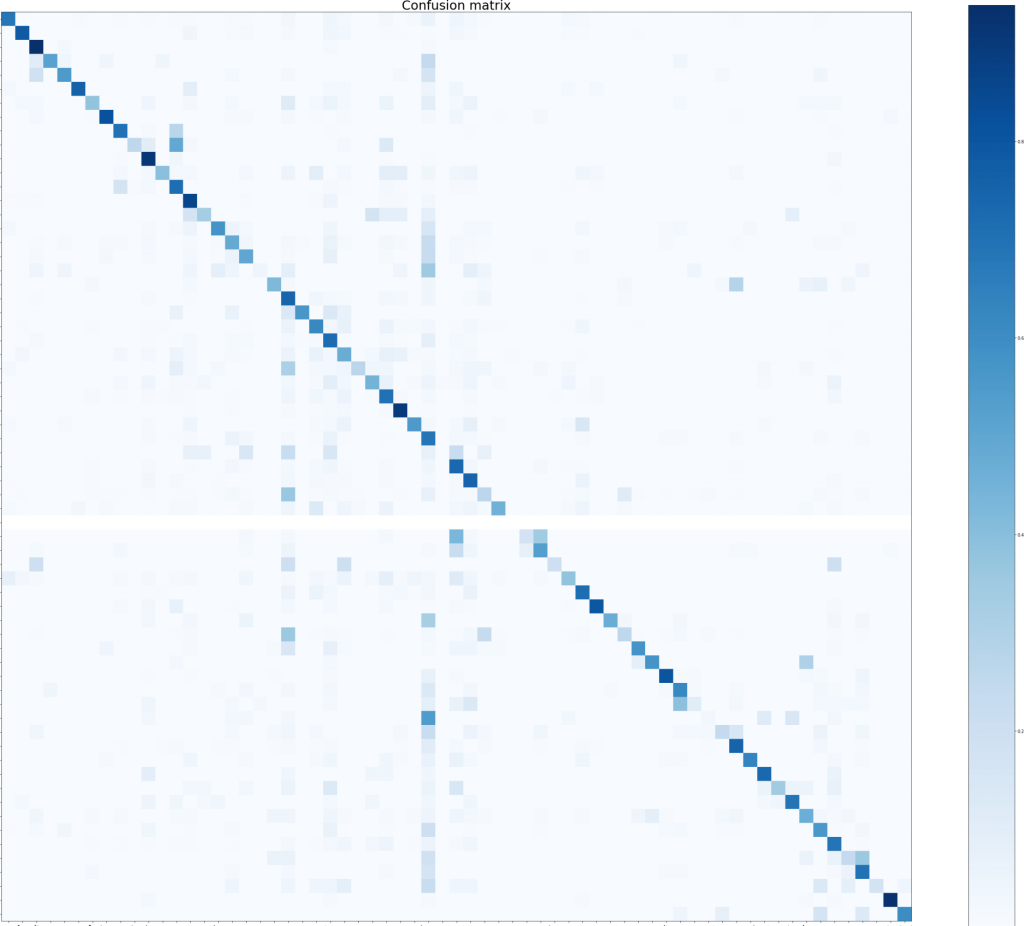
Заключение
В статье были рассмотрены процессы сбора, предварительной обработки и классификации текстовых данных на примере выгруженных из СУБД 98576 заявок HelpDesk-а по 222 категориям. LSTM модель нейронной сети показала максимальную производительность (точность 98,7%) по сравнению с MLP моделью. На ваших данных результаты могу оказаться немного другими, но тем не менее, я надеюсь, у вас теперь сложилось понимание того, как происходит обработка и машинное обучение с последующей классификацией текста.











